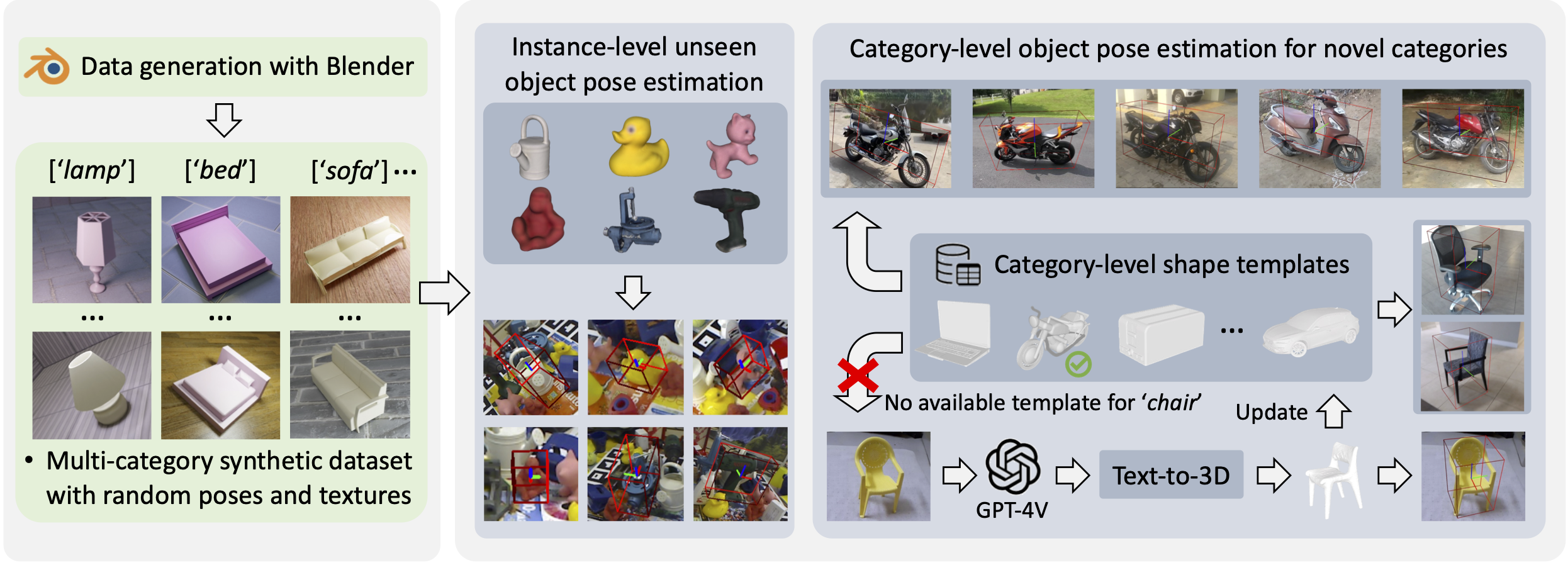
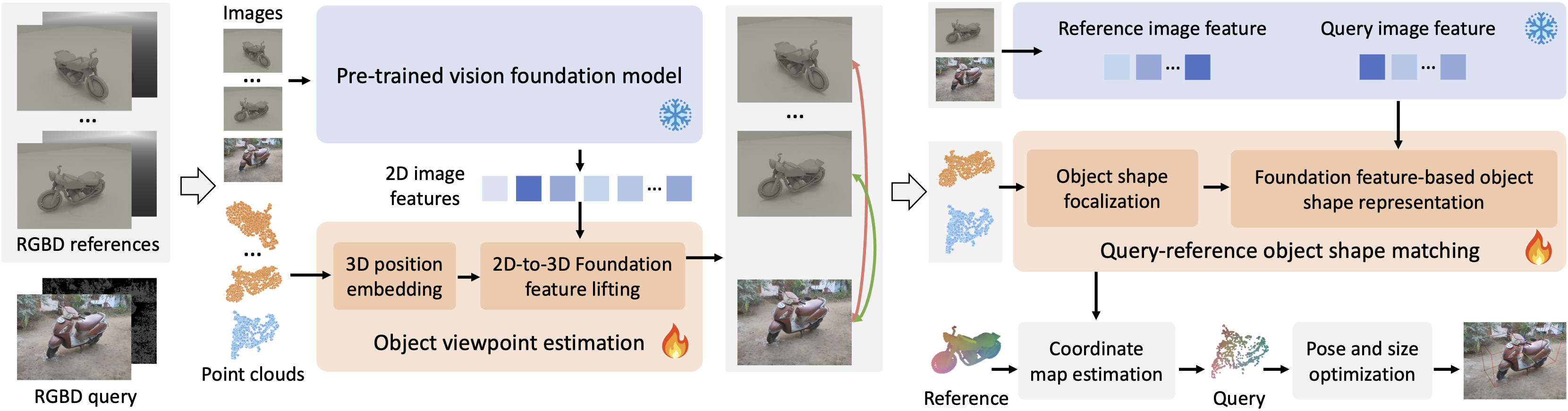
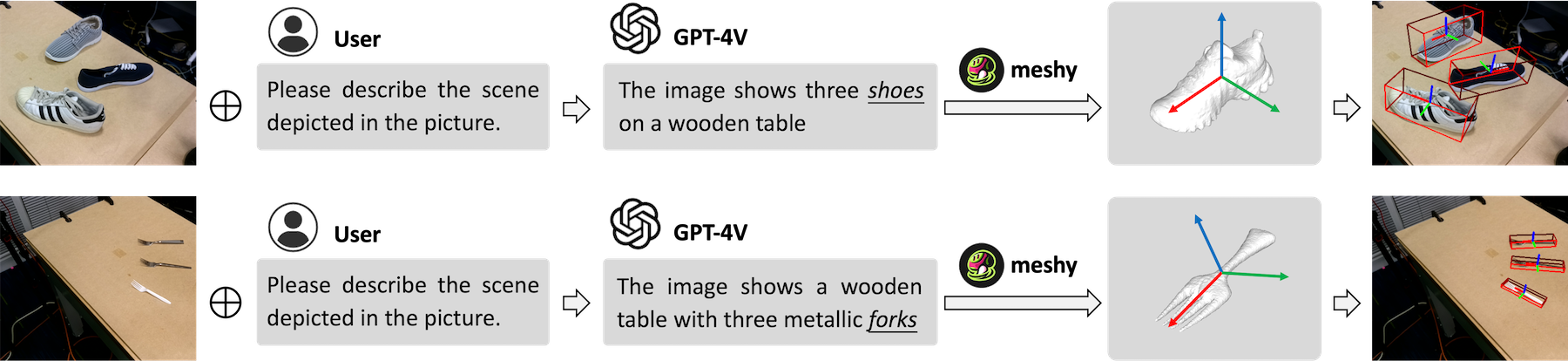
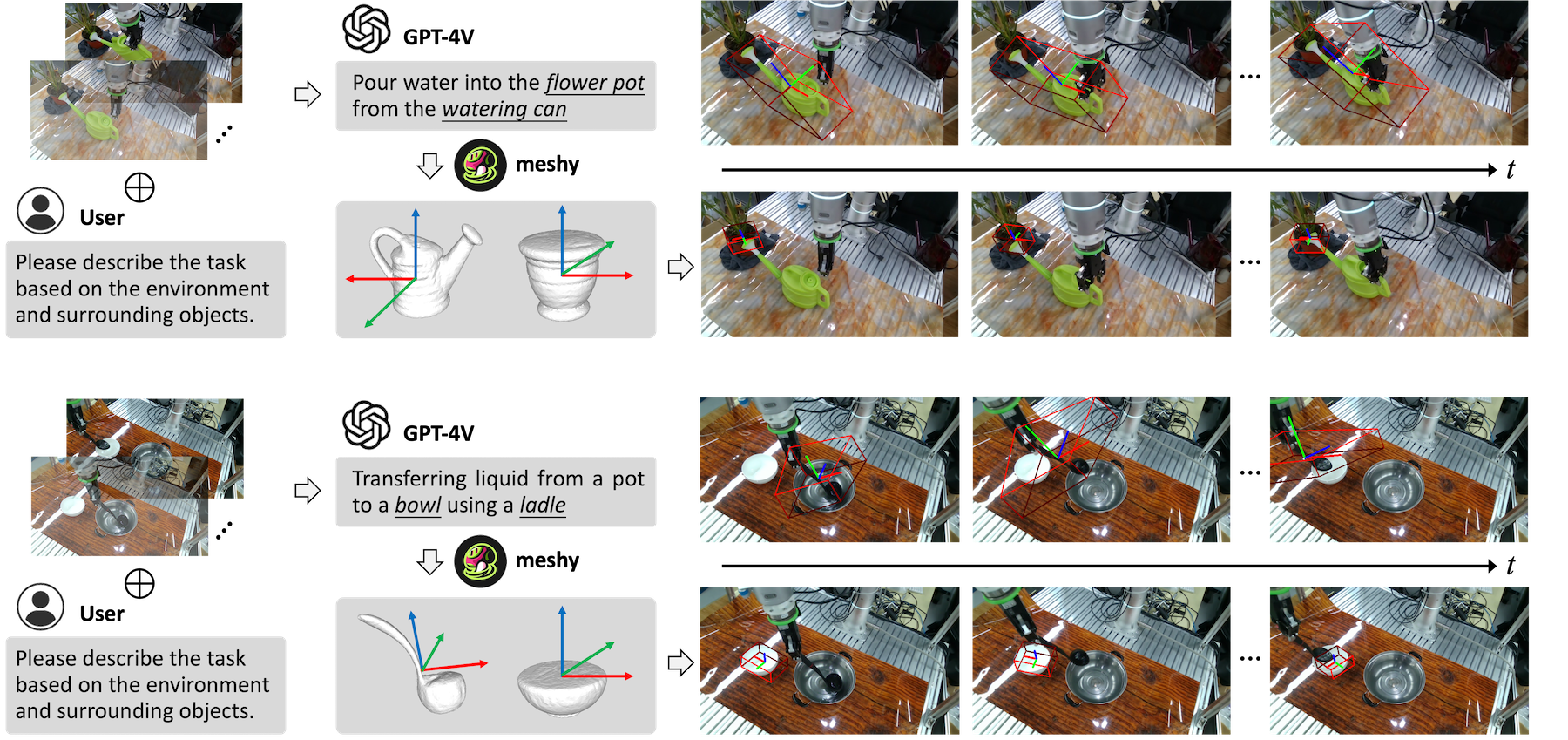
Object pose estimation plays a crucial role in robotic manipulation, however, its practical applicability still suffers from limited generalizability. This paper addresses the challenge of generalizable object pose estimation, particularly focusing on category-level object pose estimation for unseen object categories. Current methods either require impractical instance-level training or are confined to predefined categories, limiting their applicability. We propose VFM-6D, a novel framework that explores harnessing existing vision and language models, to elaborate object pose estimation into two stages: category-level object viewpoint estimation and object coordinate map estimation. Based on the two-stage framework, we introduce a 2D-to-3D feature lifting module and a shape-matching module, both of which leverage pre-trained vision foundation models to improve object representation and matching accuracy. VFM-6D is trained on cost-effective synthetic data and exhibits superior generalization capabilities. It can be applied to both instance-level unseen object pose estimation and category-level object pose estimation for novel categories. Evaluations on benchmark datasets demonstrate the effectiveness and versatility of VFM-6D in various real-world scenarios.